OCR Report Extractor Examples
Report extractors enable the user to automatically extract FHIR data from documents that share consistent structures or patterns.
Prebuilt OCR report extractors are available in the Marketplace, see Marketplace.
Example Report Extractor
To demonstrate how a Report Extractor is used, let's say your organization receives many Carbohydrate Antigen 19-9 lab reports from Labcorp. Below is an example of such report:

OCR enables the user to manually extract the data from this lab report, but with multiple reports this quickly becomes repetitive, considering all of these reports are in a nearly identical format. In fact, if you could define a simple set of rules, this extraction could be automated and executed in a very reliable manner.
To manage these report extractors, open the file and navigate to the
Data Tables section. Within the data tables section, you will see a tab for
report extractors. This is where report extractors can be created, updated, or
deleted (more on this later). The user can also manually execute a report
extractor to generate data or remove the data generated by a report extractor.
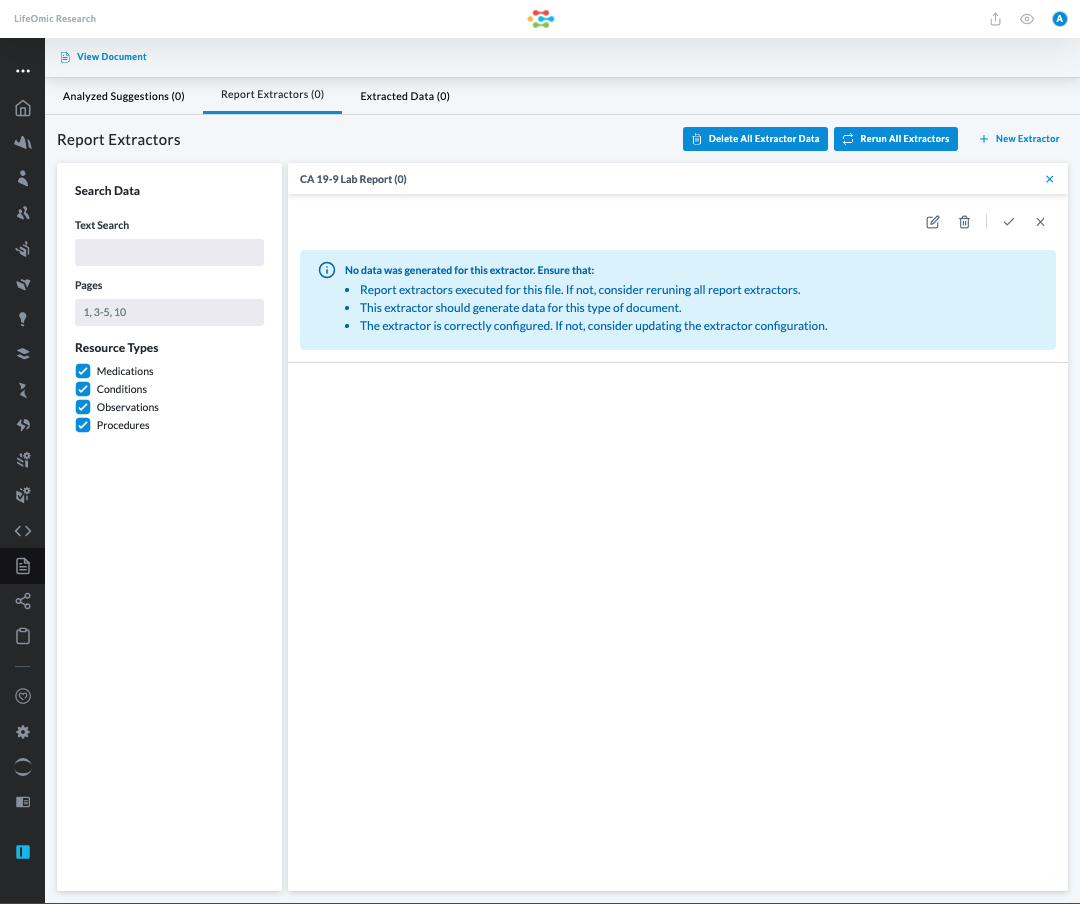
By clicking Rerun All Extractors, the CA 19-9 extractor executes. Once
this completes, you will see the extractor results within the table:
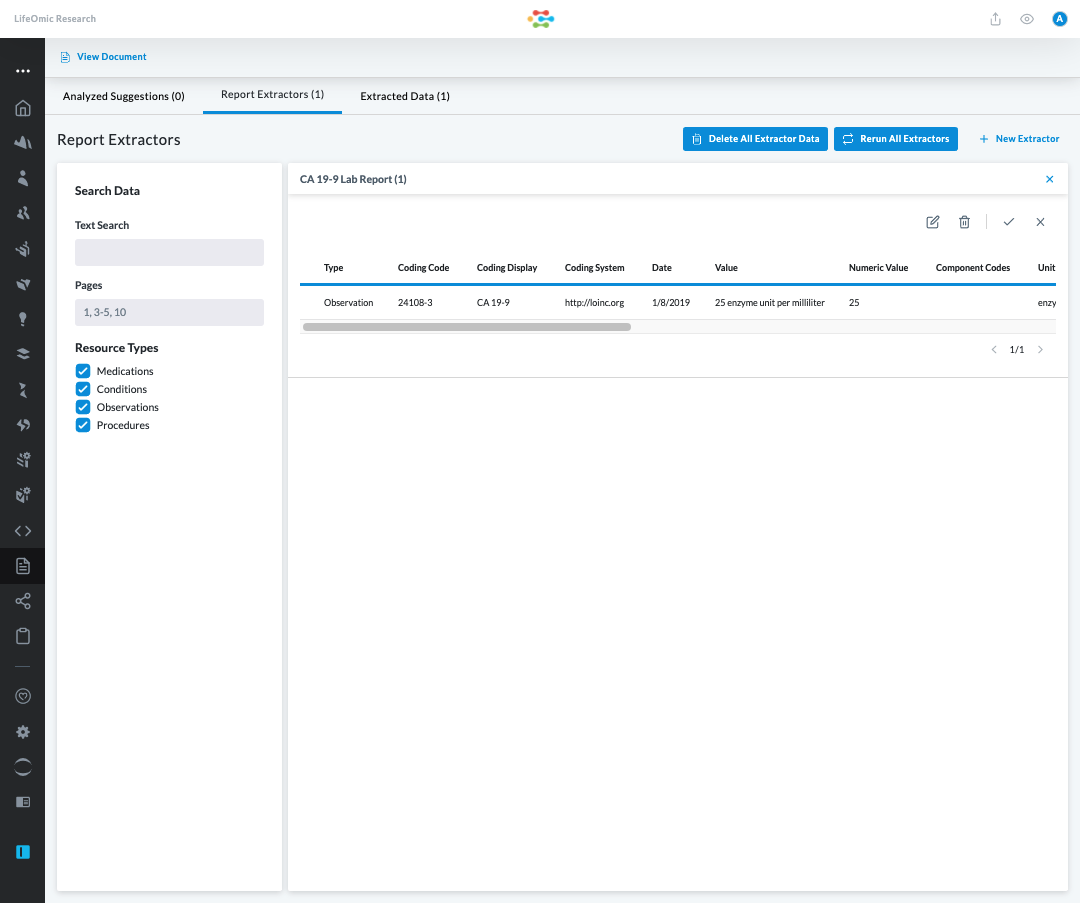
Results listed in this table are fully extracted data elements. The data elements are now persisted on the corresponding subject's record.
You must assign a subject to the document before report extractors can execute.
A user can enable report extractors to execute automatically when a document is uploaded.