Build OCR Report Extractors
OCR report extractors can be built by anyone with some technical understanding of:
- JSON
- Regular Expressions
- HL7 FHIR
Once configured, your report extractor can be used for any OCR document within a project.
Prebuilt OCR report extractors are available in the LifeOmic Platform Marketplace, see Marketplace.
For additional information on report extractors, see OC Report Extractors Examples and OC Report Extractor JSON Config.
Report Extractor Architecture
At the most basic level, a report extractor receives an OCR document as input and outputs one or more FHIR resources as the output. But how does this transformation happen?
Report extractors are executed as a series of stages using a "pipeline" style architecture. Below is an conceptual example of a three stage pipeline:

In this pipeline, stage 1 executes, then stage 2, and finally stage 3.
Aside from execution flow, this pipeline architecture also "pipes" the output from one stage to the next stage. So in the above example, the output from stage 1 is the input to stage 2. Also, the output from stage 2 is the input to stage 3. Those outputs and inputs consist of two things:
- The filtered/subset of the original document
- The partial FHIR resources that is being built
Each pipeline stage generally filters down the source document or adds to the FHIR resource that is being built.
The report extraction pipeline also includes the concept of a stage "failing." If a stage "fails," the pipeline execution is halted. The FHIR resource is never completed, and the data is never generated. A pipeline "failure" does not necessarily mean "something went wrong and your report extractor configuration is invalid." A failure could simply mean "this report extractor doesn't apply to this type of document" or "this document page can be ignored by this report extractor." Leveraging pipeline failures is a great method to help create report extractors.
Report extractor pipelines also enable "branching" your pipeline. We will get into the "why" and "how" later, but below is a conceptual example of a pipeline branch:
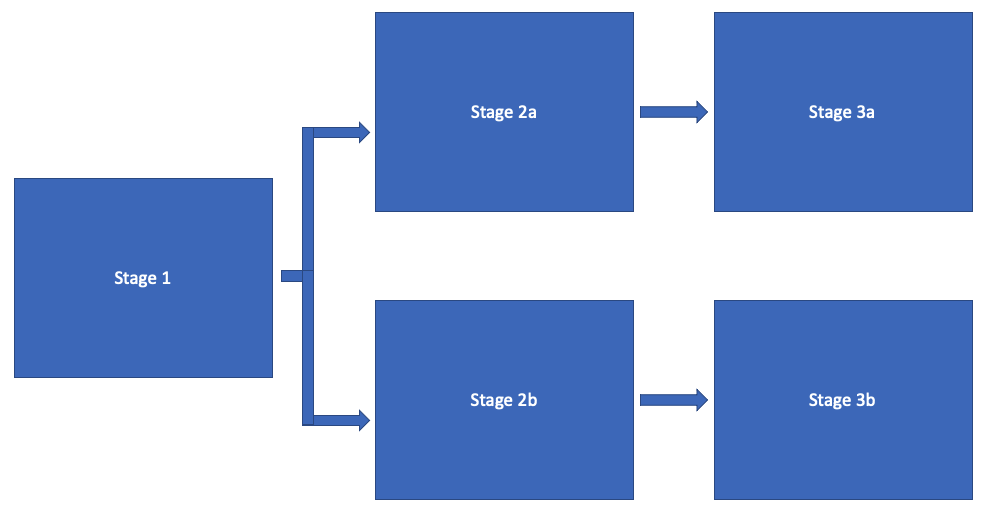
Branch pipelines handle inputs and outputs slightly differently than a straight pipeline. In this branched pipeline, the output of Stage 1 is copied. Stage 2a receives one copy for the input, and Stage 2b receives the other copy for the input.
Branched pipelines can also generate more than one pipeline output. In the branch example, Stage 3a and Stage 3b can both generate an output. This is how a single report extractor can generate a large set of different FHIR resources.
Errors are also handled a bit differently with branched pipelines. If an error occurs on a pipeline branch, no other stages along that pipeline branch execute. Stages along other branches continue to execute. Given the branched pipeline example:
- If an error happens on the main trunk in Stage one, neither branch executes.
- If an error happens on the branch in Stage 2a, then Stage 3a does not execute, but the other branch with stages 2b and 3b is not affected and executes as usual.
Report Extractor Stages
As mentioned, stages are the building blocks of the report extractor pipeline. As the designer of a report extractor, you configure a pipeline of stages that fall into one of these categories:
- Selection - a selection stage is what "filters down" a document. This enables future stages to execute on a smaller and more targeted subset of the input document. This improves extractor efficiency and accuracy.
- Value Extraction - a value extraction stage adds to and builds upon the pipeline's FHIR resource.
- Projection - a projection stage branches your pipeline.
- Assertion - an assertion stage ensures a condition is true. If the assertion fails, the stage fails, and the pipeline halts the execution.
Each stage category has its own set of allowable properties. However, some properties and functionalities can be used by any stage regardless of the category or type. All of these universal properties and functionalities are optional:
/**
* Provides user-friendly messages to stages. This can help assist with debugging and tracing
*/
description?: string
/**
* Filter the input partial document for stage execution
*/
filters?: Filters[]
/**
* A pre-condition for stage execution.
*/
condition?: Condition,
Stage Filters
Stage filters capture a subset of the input document. The following filter types are allowed:
/**
* Filters a doc for content matching the regex
*/
type RegexMatchFilter = {
type: 'regex',
/**
* If provided "scopes" the result aggregation.
* ex: if "page" is specified, any page that contains a match retains its whole contents. If you specifically look
* for a page containing "lab report", it will filter that whole page's content and not just the words "lab report"
*/
scope?: 'page' | 'line' | 'word',
regex: string,
};
/**
* Filters a doc for anything in the matched text's row. A row is defined as any line in the page that vertically
* overlaps the line of the regex match
*/
type RegexTableRowFilter = {
type: 'regex-row-match',
regex: string,
};
/**
* Filters a doc for anything in the matched text's column. A column is defined as any line in the page that horizontally
* overlaps the line of the regex match
*/
type RegexTableColFilter = {
type: 'regex-col-match',
regex: string,
};
/**
* Filters a doc for anything both in the matched row and col. It will include anything with a horizontal overlap of the
* specified col text and anything with a vertical overlap of the specified row text
*/
type RegexTableCellFilter = {
type: 'regex-table-cell-match',
rowRegex: string,
colRegex: string,
};
/**
* filters a doc page for anything overlapping the specified geometry. For example, if the user only wants to capture the bottom
* half of the page, the geometry would be:
* {Height: 0.5, Width: 1, Top, 0.5, Left: 0}
*/
type GeometryFilter = {
type: 'geometry',
geometry: {
Height: number,
Width: number,
Top: number,
Left: number,
},
};
/**
* Filters down the regex context to a specific page index (0 based)
*/
type PageNumberFilter = {
type: 'page-number',
pageNumber: number,
};
/**
* Filters successively select portions of the document
*/
type Filters =
| RegexMatchFilter
| PageNumberFilter
| RegexTableRowFilter
| RegexTableColFilter
| RegexTableCellFilter
| GeometryFilter;
Stage filters run before any of the other stage's operation and
can filter down the document to portions that are only relevant to the current
stage. It is important to note that this does not filter the output document. If
you use a PageNumberFilter to filter down to the third page of a ten page
document, then the stage will just execute using the third page, but the next
stage still receives all 10 pages. If you do wish to filter the output
document, you must use a selection stage category type.
Stage Conditions
Stage conditions ensure that a logical condition is true for the stage to
execute. If the condition is false, the stage is bypassed, and the next stage executes.
As seen below, conditions can be nested and support arbitrarily complex logic:
/**
* All conditions in conditions array must be met. Empty array evaluates to true
*/
type AndCondition = {
type: 'and',
conditions: Condition[],
};
/**
* Any conditions in conditions array must be met. Empty array evaluates to true
*/
type OrCondition = {
type: 'or',
conditions: Condition[],
};
/**
* Condition must not be true
*/
type NotCondition = {
type: 'not',
condition: Condition,
};
/**
* Regex result must match any result in the values array.
*/
type RegexMatchCondition = {
type: 'regex-match',
matchGroup?: boolean,
regex: string,
values: string[],
};
/**
* Context must pass the given regex test
*/
type RegexTestCondition = {
type: 'regex-test',
regex: string,
};
/**
* The target property in the current resource must be set
*/
type ResourcePropertySetCondition = {
type: 'resource-property-set',
targetProperty: string,
};
/**
* Conditions can be applied to any stage.
* If the condition is met, the stage is executed.
* If the condition is not met, the following stage is executed. No extraction error is thrown.
*/
type Condition =
| AndCondition
| OrCondition
| NotCondition
| RegexMatchCondition
| RegexTestCondition
| ResourcePropertySetCondition;
Selection Category
Document selection stages filter the input document and output the filtered document to the next stage. Selection stages are defined as such:
type SelectionStage = {
category: 'selection',
type: 'doc-filter',
};
Value Extraction
Value extraction stages update the input FHIR resource using any of the multiple stage types below:
/**
* Types will be casted from the input string to the specified type
*/
type ValueExtractionTypes = 'dateTime' | 'decimal' | 'string';
type ValueExtractionFormatOptions = {
/**
* The value extractor step will convert between two valid UCUM units: https://ucum.nlm.nih.gov/ucum-lhc/
* If the units are not valid or translatable with each other or the input value is not numeric, a runtime error will be thrown
*/
unitConversion?: {
/**
* The UCUM code of the unit the extracted value is converted from
*/
fromUnitCode: string,
/**
* The UCUM code of the unit the extracted is converted to
*/
toUnitCode: string,
},
};
/**
* Will use a regex match and use the first match to use as the assigment value
*/
type RegexMatchValueExtraction = {
category: 'set-value',
type: 'regex-match',
/**
* The regex to match with
*/
regex: string,
/**
* The type the value will be casted to
*/
valueType: ValueExtractionTypes,
/**
* The target property it will be set to. This uses the lodash setter convention
*/
targetProperty: string,
/**
* If no value is found or no type can be casted the stage will result in a failure
*/
isRequired: boolean,
/**
* Whether or not a matched group should be the output and assigned value of the regex
*/
matchGroup?: boolean,
/**
* Options for formatting the resulting extracted value
*/
formatOptions?: ValueExtractionFormatOptions,
};
/**
* This will default the resource value to the specified value. Note that this will overwrite
* any resource value in the value extraction context and default properties will be added after this operation (subject ID, project, etc)
*/
type DefaultResourceValueExtraction = {
category: 'set-value',
type: 'default',
default: any,
};
/**
* This will default the resource value to the specified value at the specific property.
* This does not overwrite the existing value
*/
type StaticSetterValueExtraction = {
category: 'set-value',
type: 'static',
value: any,
/**
* The target property it will be set to
*/
targetProperty: string,
};
/**
* Value extraction stages are stages that specifically update the resulting resource
*/
type ValueExtractionStage =
| RegexMatchValueExtraction
| DefaultResourceValueExtraction
| StaticSetterValueExtraction;
Projections
Projection stage types will split the current pipeline into multiple pipelines. There is no limit to how many times a pipeline can be split. Projections can be done in any of the following ways:
/**
* A projection step that splits its extraction context into multiple unique branches.
*/
type BranchProjection = {
category: 'projection',
type: 'branch',
branchPipelines: Stage[][],
};
/**
* A projection step that splits the extraction context into pipelines by each page.
* Each branch will create its own resource.
*/
type PageMapProjection = {
category: 'projection',
type: 'page-map',
mapPipeline: Stage[],
};
/**
* A projection step that splits the extraction context into pipelines by each line (doc line, not textract line)
* Each branch will create its own resource if one is successfully generated.
*/
type LineMapProjection = {
category: 'projection',
type: 'line-map',
mapPipeline: Stage[],
};
type ProjectionStage = BranchProjection | PageMapProjection | LineMapProjection;
Assertions
Assertion stages ensure that the given stage condition check is true. If it is
false, the pipeline fails.
/**
* An assertion step that will inspect the extraction context and assert that the text matches the given regex
*/
export type RegexMatchAssertion = {
category: 'assertion',
type: 'regex-match',
regex: string,
};
/**
* An assertion step that evaluates a condition. If the condition is false, the branch fails
*/
export type ConditionAssertion = {
category: 'assertion',
type: 'condition',
assertionCondition: Condition,
};
export type AssertionStage = RegexMatchAssertion | ConditionAssertion;